Nitro Components
Nitro’s core purpose is to answer questions that business stakeholders are asking of commercial data. To do this, Nitro must gather lots of data into one central location, then aggregate, combine, and enrich this data so business intelligence can be generated to answer these questions.
The general lifecycle of data in the Nitro universe starts with a source provider or source system. This data enters Nitro through a connector. Depending on the source, whether it is an application platform, a syndicated third-party data asset, or simply an important spreadsheet, a specific type of connector is used to load the data into Nitro.
Once data is loaded into Nitro, cleansing, data model instantiation/manipulation, history tracking, data aggregation, and general data enrichment processes are executed. Nitro is divided into specific conceptual layers, where each is responsible for a particular type of data processing.
The final form of the data within Nitro exists in the reporting layer, which allows business intelligence tools, including Nitro Explorer, to access it.
External tools can pull data from the Nitro reporting layer into their own database for visualization and further analysis. Veeva CRM MyInsights is one of the key consumers of Nitro data. Nitro has a direct integration with each Veeva CRM mobile platform so Nitro data can be synced down and accessed in a disconnected state via the MyInsights platform.
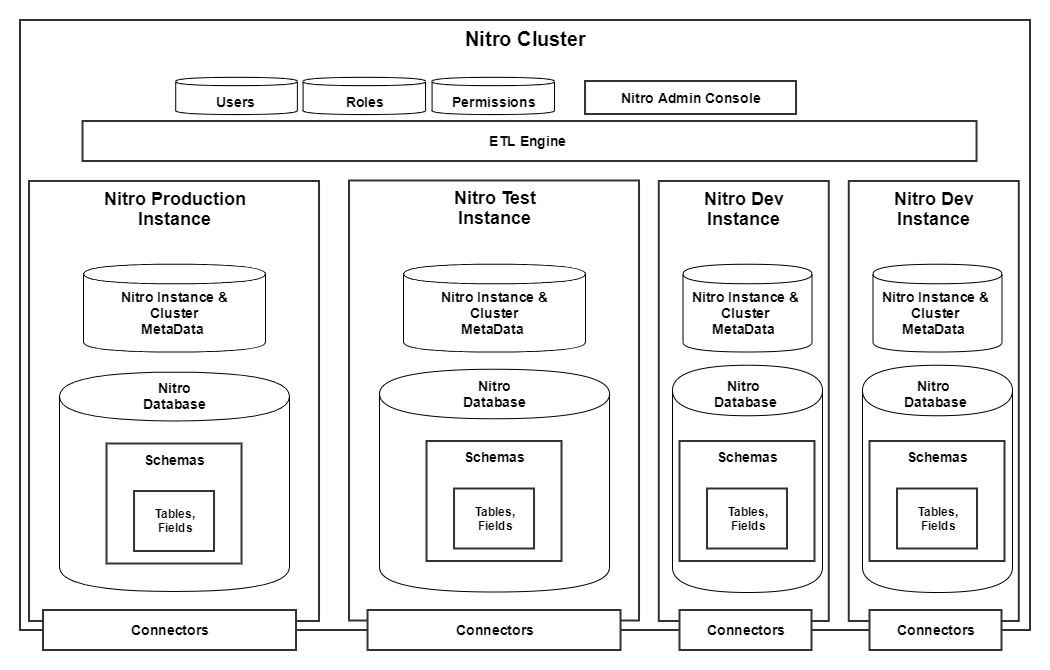
Nitro Cluster
Nitro customers are provisioned a Nitro cluster. A cluster is the top-most architectural concept. All other components live within the cluster. A Nitro administrator accesses the Nitro Cluster by navigating to the Nitro Admin Console. From the console, an administrator can view the overall health of the Nitro Cluster and can look into individual Nitro Instances to view details.
Nitro Instances
A Nitro Instance is a virtual wrapper around the data and metadata. Nitro instances are physically and logically separated from one another according to their function. A Nitro instance is the next level down from a Nitro Cluster in the architecture. There are many Instance types.
Nitro Instance Types
- Production Instance - The production instance represents the data and processes available to your end users
- Test Instance - The Test instance is similar to the production instance and serves as the final integrated testing group for changes prior to deployment of those changes into production
- Dev Instance - The Dev instance is a sandbox used by developers and data-level administrators to experiment and build new functionality
Nitro Instance Database Components
- Database - Each Nitro Instance is attached to a single Redshift database
- Schemas - Schemas are logical groupings of tables and fields. Each database within an instance contains one or more schemas.
Nitro Connectors
Data and metadata from external sources are integrated into the Nitro ecosystem using Connectors. Nitro supports the following connector types:
- Intelligent Sync Connector Library - Pre-built connectors to other application platforms to import both metadata and data automatically into Nitro. Changes in the external data structures are propagated automatically into Nitro without any development effort required. An example of this type of connector is the Veeva CRM Intelligent Sync Connector.
- Industry Data Connector LIbrary - Out of the box, pre-built connectors that integrate data assets into Nitro. The scope of this type of connector includes both data assets owned by Veeva and third-parties. These connectors leverage SFTP and ETL processes to import data into Nitro and process it according to standard business logic. An example of this type of connector is the Symphony Sales Data Connector.
- Custom Connectors - Not all data/metadata in Nitro comes from a Veeva connector. In some cases, it is necessary to connect Nitro to a very specific, custom data source. To do this, build a custom connector. Custom connectors leverage SFTP to import data into custom-built schemas in Nitro.
Nitro Database Layers
A Nitro database layer is a virtual concept within the database that groups schemas according to the type of processing applied to and usage of data. Data flows through the layers from the bottom up incurring various forms of processing along the way in order to produce the final data set.
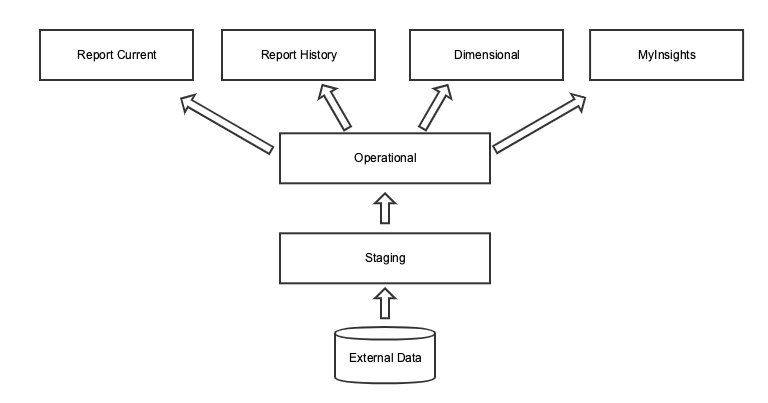
In metadata, Nitro stores the layer a schema belongs to as an attribute of the schema object.
Out of the box, Nitro leverages the following conceptual layers:
- Nitro Staging (‘stg’) - The staging layer of Nitro is the landing zone for all of the raw data being integrated into the database. This data resides in data structures that are a one-to-one match with the source data format. Data in this layer is not ready for reporting.
- Nitro Operational Data Store (‘ods’) - The ods is similar to what is in staging with some distinct differences:
- If applicable, effective dating processing has occurred. Effective dating involves tracking and recording any and all changes that happen to a particular record over time. Tables in the ods that are effective dated carry start date and end date fields that allow downstream processes and queries to pick out the version of the record needed according to a date filter.
- Unused or unnecessary columns are dropped from the staging version of the table structures
- Nitro Dimensional Data Store (‘dds’) - The dds houses Veeva-delivered and customer-built dimension and fact tables (stars). Other tables supporting the star tables may also reside here, for example, lookup/mapping tables. Business intelligence (BI) tools access this layer to build and generate reports.
- Nitro Current Reporting Data Store (‘report_current’) - The report_current layer holds views that point at data in the ods. The views here represent the latest version of the data, meaning the query looks for rows in the ods where the end_date__v is NULL. BI tools access data in this layer to get the latest version of data directly from the external data source.
- Nitro History Reporting Data Store (‘report_history’) - Like the report_current layer, the report_history layer is intended to give BI tools access to the data in the ods. The views in this layer, however, include all rows from the ods. In the case of effective date tables in the ods, the entire history is exposed.
- Nitro MyInsights (‘myinsights’) - The myinsights layer sits above the ods and is used exclusively to support Veeva CRM MyInsights modules. Views in this layer are synced to Veeva CRM mobile platforms for consumption by the MyInsights reporting tool.
Nitro Namespaces
Nitro namespaces are used to classify schemas, fields, tables, and other pieces of metadata according to function and origin. There are three namespaces the Nitro customer interacts with.
- Veeva (v) - The Veeva namespace is applied to databases, tables, and fields. It indicates these structures are managed by Veeva
- Default - If a namespace is not specified, the namespace defaults to blank (no underscores applied)
- Custom - Nitro customers can create their own namespaces
Nitro Jobs
Jobs are what generate connector operations, tables, and views in various schemas within Nitro. Jobs can be run ad-hoc or scheduled via the Admin Console.
Jobs have a specific structure:
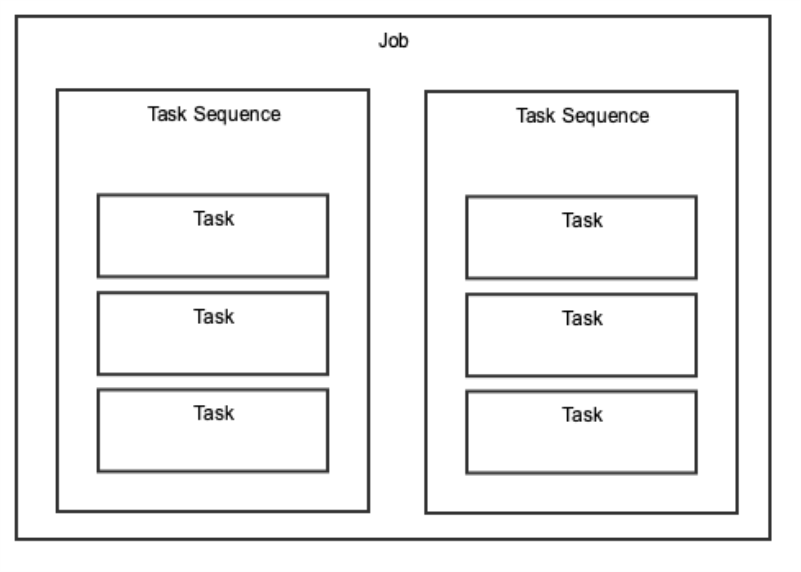
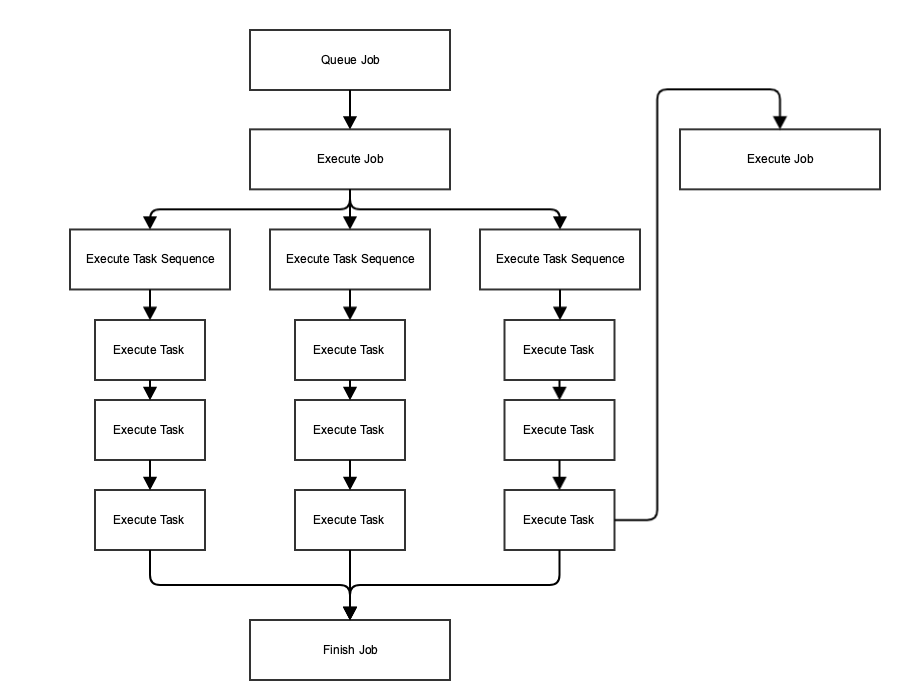
A Job is made up of task sequences which include individual tasks. Tasks can either run SQL scripts, execute python routines, or queue jobs. Task sequences run in parallel while tasks run sequentially.
Nitro Packages
A Nitro package is a file-based grouping of metadata and sql/application scripts deployed to a specific Nitro instance that controls the schema and data processing. Some Nitro packages are owned and managed by Veeva, whereas others are owned and managed by the customer. Namespaces are used to identify ownership and control of packages.
Within a Nitro package directory there are several subdirectories that group the various metadata components and sql/application scripts according to function:
- jobs - this directory contains .yml files to define the task sequences run as a part of the job
- taskSequences - this directory contains .yml files to define the order of tasks to be executed. These are referenced by the job .yml file.
- tasks - this directory can contain .sql (SQL script). These are referenced by task sequences .yaml files.
- tables - this directory contains .yml files to define the tables and fields that are a part of the package. These are referenced by tasks of type .sql and are performing DDL operations.
- allowlists - this directory contains configurations specific to Intelligent Sync Connector functionality. These are .yml files that specify object level and field level configuration used when executing an Intelligent Sync Connector data load.
- patterns
- scripts
- dataQualityRules - this folder is included as part of the standard metadata package download, and can be uploaded into any instance or connector.
See Uploading Metadata Packages Using the NAC for more information.

