Intelligent Object Connectors for Custom Data Sources
Admins can use Intelligent Object Connectors to integrate custom data sources without the need to create table definition files. This feature allows admins to load custom files automatically using an Intelligent Object connector, then access those files as any other view using the connector’s database report schemas.
To use Intelligent Object Connectors for Custom Data Sources:
-
Log into the NAC.
-
Select Inbound Connectors from the Connectors section of the side menu.
-
Select the New Connector button.
-
Add connector details including display name and description.
-
Select Custom (Intelligent Objects) as the connector type under Intelligent Objects.
-
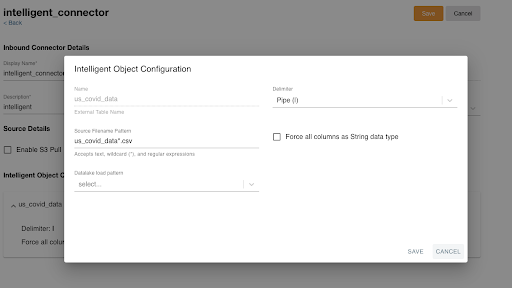
Create an Intelligent Object Configuration for each file you want to load by selecting Add.
-
Enter the following information:
- Name - Enter the name to be used for table in Nitro. Nitro automatically appends an __c to the table name.
- Delimiter - Select the type of delimiter used in the data file(s)
- Pipe
- Comma
- Semi-colon
- Tab
- Source Filename Pattern - Enter the filename pattern to identify which files to load to the table
- Force all columns as String Data type - Nitro determines the data type of the columns. Users have the option to force all columns of the source data to be loaded as type String. If data types are not read correctly, this option allows users to load the data consistently.
- Data Lake Load Pattern:
- Full Truncate and Insert Data - This pattern always deletes the existing data in the table and replaces it with the new data files, when new files are loaded
- Append Data - This pattern appends the existing data with all new files loaded to this table where table metadata is the same. If table metadata changes, a new table must be created.
-
Select Save.
To start the metadata discovery and load process:
The maximum recommended size for Parquet files is 150MB per file.
Spaces in the file name and in the header row are not supported for Intelligent Objects.
- Load files into the upload folder using one of two methods:
-
Once files are uploaded or S3 is set up, run the appropriate job as listed in the following table:
Job Name Description Nitro S3 Pull Files
Copies files from the source S3 location into the upload folder for this connector
Data Lake Intelligent Load Loads files from the upload folder in sequential order, one intelligent object configuration at a time. Only one job is listed in Nitro. Data Lake Connector Load
Copies files from the source S3 location and loads files concurrently into Nitro. Supports file batching. Each intelligent object configuration is listed as an individual job in Nitro. If files exist in the upload folder, this job loads those files first, then any additional files in S3, if a source S3 is set up.
To access the data, users must view the Report Current or Report History schema using a BI tool, for example, Nitro Explorer.

